Markov Decision Process
Bellman Equation
Dynamic Programming
Model-free Prediction
Model-free Control
Value Function Approximation
Policy gradients
Actor-critic methods
In the reinforcement learning set up, we have a system with states and dynamics among states. Dynamics consist of probabilities for transitions among states and rewards for states. And, there is an agent who can take one of several possible actions in each state. The goal is for the agent to act at each point of time in such a way as to maximize cumulative reward.
Reinforcement Learning is mathematically modeled by a Markov Decision process (MDP).
Markov Decision Process
An MDP is formalized as a tuple ")
: set of states
: set of actions that can be taken on states
: a set of matrices where each matrix gives probabilities of transitions from one state to another (Markov property implies current state is good enough to indicate probability of transition to a subsequent state). Rather than one matrix, we need a set of matrices because probabilities of state transitions are dependent on actions taken on the states. So, each matrix in the set is indexed by an action. Thus, an element of a matrix for action
, denoted
, is the probability of transitioning to state
, when action
.
: This is a set of vectors of rewards(or, precisely, expectation of reward). Each vector gives reward out of a particular state. Thus, an element of vector for state
is the reward that is given for taking action
: This is the discount factor that is multiplied to future rewards to determine the value of current state or an action in current state.
Goal of an MDP is to determine a decision policy 
")
A state-value function ")
")

")
Bellman Equation
![\begin{aligned}v_{\pi}(s) &= \sum\limits_a \pi(a|s)\left[R_s^a+\gamma\sum\limits_{s'} P^a_{ss'}v_{\pi}(s')\right] \\ q_{\pi}(s,a) &= R_s^a+\gamma\sum\limits_{s'} P^a_{ss'}\left[\sum\limits_{a'}\pi(a'|s')q_{\pi}(s',a')\right]\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7Dv_%7B%5Cpi%7D%28s%29+%26%3D+%5Csum%5Climits_a+%5Cpi%28a%7Cs%29%5Cleft%5BR_s%5Ea%2B%5Cgamma%5Csum%5Climits_%7Bs%27%7D+P%5Ea_%7Bss%27%7Dv_%7B%5Cpi%7D%28s%27%29%5Cright%5D+%5C%5C+q_%7B%5Cpi%7D%28s%2Ca%29+%26%3D+R_s%5Ea%2B%5Cgamma%5Csum%5Climits_%7Bs%27%7D+P%5Ea_%7Bss%27%7D%5Cleft%5B%5Csum%5Climits_%7Ba%27%7D%5Cpi%28a%27%7Cs%27%29q_%7B%5Cpi%7D%28s%27%2Ca%27%29%5Cright%5D%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0 "\begin{aligned}v_{\pi}(s) &= \sum\limits_a \pi(a|s)\left[R_s^a+\gamma\sum\limits_{s'} P^a_{ss'}v_{\pi}(s')\right] \\ q_{\pi}(s,a) &= R_s^a+\gamma\sum\limits_{s'} P^a_{ss'}\left[\sum\limits_{a'}\pi(a'|s')q_{\pi}(s',a')\right]\end{aligned}")
 = \sum\limits_{a}\pi(a|s)q_{\pi}(s,a)")
 = R_s^a + \gamma \sum\limits_{s'}P^a_{ss'}v_{\pi}(s')")
In matrix-vector form, we can write:

Here,


R_s^a")

P_{ss'}^a")
Optimal value functions/optimal policy
Optimal state-value function ")
 = \max\limits_{\pi} v_{\pi}(s)")
Optimal action-value function ")
 = \max\limits_{\pi} q_{\pi}(s,a)")
Theorem: A policy 
That is,  = v_*(s)")

 = q_*(s,a)")

There could be multiple optimal policies for a system. But, all of them achieve 

Bellman Optimality equation
Given optimal state-value and action-value functions, we can have a particular deterministic optimal policy
 = \begin{cases} 1 & \mbox{ if } a = arg\max\limits_{a'} q_*(s,a') \\ 0 & \mbox{ otherwise }\end{cases}")
For this particular optimal policy, the following equation holds:
 = \max\limits_a q_{\pi_*}(s,a)")
This is called the Bellman optimality equation.
Note that, while the regular Bellman equation holds for any policy
Now, as given by the theorem in previous section, since
 = \max\limits_a q_*(s,a)")
Thus, Bellman optimality equation is an equation for optimal value functions.
Equivalently, Bellman optimality equation is also:
![v_*(s) = \max\limits_a\left[R^a_s + \gamma\sum\limits_{s'}P^a_{ss'}v_*(s')\right]](https://s0.wp.com/latex.php?latex=v_%2A%28s%29+%3D+%5Cmax%5Climits_a%5Cleft%5BR%5Ea_s+%2B+%5Cgamma%5Csum%5Climits_%7Bs%27%7DP%5Ea_%7Bss%27%7Dv_%2A%28s%27%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "v_*(s) = \max\limits_a\left[R^a_s + \gamma\sum\limits_{s'}P^a_{ss'}v_*(s')\right]")
And,
![q_*(s,a) = R^a_s + \gamma\sum\limits_{s'}P^a_{ss'}v_*(s') = R^a_s + \gamma\sum\limits_{s'}P^a_{ss'}\left[\max\limits_{a'} q_*(s',a')\right]](https://s0.wp.com/latex.php?latex=q_%2A%28s%2Ca%29+%3D+R%5Ea_s+%2B+%5Cgamma%5Csum%5Climits_%7Bs%27%7DP%5Ea_%7Bss%27%7Dv_%2A%28s%27%29+%3D+R%5Ea_s+%2B+%5Cgamma%5Csum%5Climits_%7Bs%27%7DP%5Ea_%7Bss%27%7D%5Cleft%5B%5Cmax%5Climits_%7Ba%27%7D+q_%2A%28s%27%2Ca%27%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "q_*(s,a) = R^a_s + \gamma\sum\limits_{s'}P^a_{ss'}v_*(s') = R^a_s + \gamma\sum\limits_{s'}P^a_{ss'}\left[\max\limits_{a'} q_*(s',a')\right]")
The difference between the Bellman equation and the Bellman optimality equation is that the average factor ")

Dynamic Programming
Two techniques from Dynamic Programming may be employed to figure out the optimal policy in the reinforcement learning set up.
The first one is called the policy iteration, while the second one is called value iteration.
Policy Iteration
Here, we start with an arbitrary policy 

We then iterate through the Bellman equation as follows:
![v^{k+1}_{\pi_0}(s) = \sum\limits_a\pi_0(a|s)\left[R_s^a + \gamma\sum\limits_{s^1}P^a_{ss'}v^k_{\pi_0}(s)\right]](https://s0.wp.com/latex.php?latex=v%5E%7Bk%2B1%7D_%7B%5Cpi_0%7D%28s%29+%3D+%5Csum%5Climits_a%5Cpi_0%28a%7Cs%29%5Cleft%5BR_s%5Ea+%2B+%5Cgamma%5Csum%5Climits_%7Bs%5E1%7DP%5Ea_%7Bss%27%7Dv%5Ek_%7B%5Cpi_0%7D%28s%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "v^{k+1}_{\pi_0}(s) = \sum\limits_a\pi_0(a|s)\left[R_s^a + \gamma\sum\limits_{s^1}P^a_{ss'}v^k_{\pi_0}(s)\right]")
Or, matrix-vector form:

Here, 
")
")
 = 0")
When we iterate over \to v_{\pi_0}(s)")

Once we thus obtain ")

 = \begin{cases} 1 & \mbox{ if } a = arg\max\limits_{a'} q_{\pi_0}(s,a') \\ 0 & \mbox{ otherwise }\end{cases}")
Then again, we determine iteratively ")
We continue this process iteratively of obtaining a new policy 
")
Value Iteration
In this method, we iterate directly using the Bellman optimality equation:
![v_*(s) = \max\limits_a\left[R_s^a + \gamma\sum\limits_{s'}P^a_{ss'}v_*(s')\right]](https://s0.wp.com/latex.php?latex=v_%2A%28s%29+%3D+%5Cmax%5Climits_a%5Cleft%5BR_s%5Ea+%2B+%5Cgamma%5Csum%5Climits_%7Bs%27%7DP%5Ea_%7Bss%27%7Dv_%2A%28s%27%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "v_*(s) = \max\limits_a\left[R_s^a + \gamma\sum\limits_{s'}P^a_{ss'}v_*(s')\right]")
We again arbitrarily initialize
![v_*^{k+1}(s) = \max\limits_a\left[R_s^a + \gamma\sum\limits_{s'}P^a_{ss'}v_*^k(s')\right]](https://s0.wp.com/latex.php?latex=v_%2A%5E%7Bk%2B1%7D%28s%29+%3D+%5Cmax%5Climits_a%5Cleft%5BR_s%5Ea+%2B+%5Cgamma%5Csum%5Climits_%7Bs%27%7DP%5Ea_%7Bss%27%7Dv_%2A%5Ek%28s%27%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "v_*^{k+1}(s) = \max\limits_a\left[R_s^a + \gamma\sum\limits_{s'}P^a_{ss'}v_*^k(s')\right]")
iteratively to derive new values of
Eventually, the process converges. That is, as  \to v_*(s)")
Model-free prediction
Dynamic programming enables us to determine the state-value and action-value functions given the dynamics (model) of the system. It does this by mathematically using the Bellman equations and plugging in the dynamics (rewards and probabilities).
If the model (rewards and probabilities) of the system is not known a priori, we can empirically estimate the value functions for a given policy. We do this by taking actions according to the given policy, and taking note of the state transitions and rewards. By making enough number of trials, we are able to converge to the value functions for the given policy.
Monte-Carlo learning
This applies to experiments which are run as episodes. Each episode terminates and next episode is independent of the current episode. As an example, when a board game is played, each new game constitutes a separate episode.
Given a policy, action is taken in each state according to the policy. For a state 

Here, 
Such returns 
 \leftarrow S(s) + G_t")
And, number of episodes (or in an alternate method, number of visits??) ")
Value of the state is estimated as mean return  = \frac{S(s)}{N(s)}")
\rightarrow V_{\pi}(s)")
\rightarrow \infty")
Note that running average return can calculated online (real-time) as the episodes are run instead of calculating it only after all episodes are completed as follows:
 \leftarrow V(S_t) + \frac{1}{N(S_t)}(G_t - V(S_t))")
Or equivalently,
 \leftarrow \left(1 - \frac{1}{N(S_t)}\right)V(S_t) + \frac{1}{N(S_t)}G_t")
In practice in online learning scenario, rather than using }")


 \leftarrow (1 - \alpha)V(S_t) + \alpha G_t = V(S_t) + \alpha(G_t - V(S_t))")
What is the reasoning? Rather than the average over all episodes, returns from recent episodes is given more weight than returns from old episodes. Returns from episodes are given weights that exponentially decrease with time.
Temporal-Difference (TD) learning
In contrast to Monte-Carlo learning, Temporal-Difference (TD) learning can learn the value function for non-episodic experiments.
In Monte-Carlo learning, we run through a complete episode, note the “real” return obtained through the end of the episode and accumulate these real returns to estimate the value of a state.
In TD learning, we do as follows:
- we initialize the value for each state.
- we run the experiment (according to the given policy) for a certain number of steps (not necessarily to the end of the episode or experiment). The number of steps
we run the experiment is identified as
- we note the reward obtained in these steps.
- We then use the Bellman equation to estimate the return for the remaining of the experiment. This estimated return is
. This estimated total return
is called TD target.
- We update
similar to online Monte-Carlo learning except that here, we use estimated return rather than the “real” return. That is, we update using:
. The quantity
is called TD error.
How do we determine 
\sum\limits_{n=1}^{\infty}\lambda^{n-1}G_t^{(n)}")
Then, we update
\leftarrow V(S_t)+\alpha\left(G_t^{\lambda} - V\left(S_t\right)\right)")
Model-free control
Model-free prediction attempts to find state-value and/or action-value functions empirically (when the dynamics of the system are not known a priori) for a given policy. As opposed to this, model-free control attempts to find optimal value functions (state-value and/or action-value) for a system empirically across all policies.
For model-free control, we combine the ideas from both model-free prediction and dynamic programming. Like dynamic programming, we iterate over policies improving the policy each time. Like Monte-Carlo and TD methods from model-free prediction, we estimate the value empirically by taking actions and observing the rewards.
Here is the intuition how the ideas combine:
- start with an arbitrary policy
- take action based on the policy
- observe rewards, update value (based on Monte-carlo or TD method)
- once value function for policy is obtained, derive new policy that acts greedily on the value function
- iterate
The following diagram illustrates the idea:
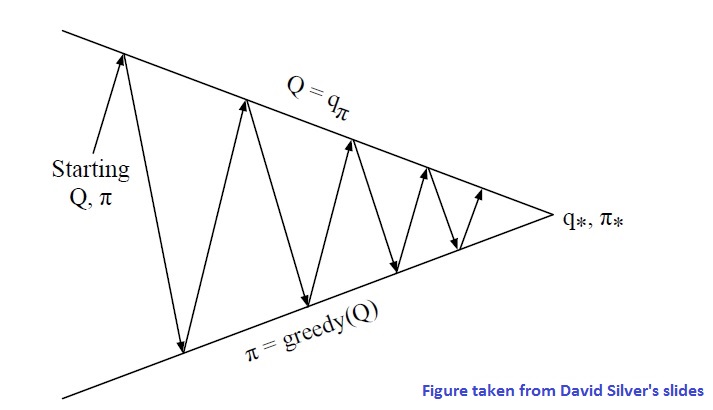
There are two points that need to be fixed in this setup:
- instead of using Monte-carlo or TD methods for state-value function estimation, use them to estimate action-value function. Knowing action-value function
allows to readily choose greedy action for a given state as in
.
- by acting greedily on the value function that is derived empirically (rather than full knowledge of dynamics), there is a chance some state or action has not been tried enough, and a potential reward is ignored. This brings the key idea of exploration. So, in deriving the new policy, we act greedily on the obtained value function with a certain probability, but also take a random action with some
probability. This is called
 = \begin{cases} \frac{\varepsilon}{m} + 1 - \varepsilon & \mbox{ if } a = arg\max\limits_{a\in A} Q(s,a) \\ \frac{\varepsilon}{m} & \mbox{ otherwise }\end{cases}")
Then, to strike a balance between eventually converging to the optimal action-value function and exploration (GLIE idea), we could make
For example, GLIE Monte-Carlo control algorithm is as follows:
- Initialize
- Start off with an arbitrary policy
- Sample the policy for an episode
- For each state
and action
in the episode,
- Improve policy as follows:
- Iterate
 & \leftarrow N(S_t, A_t) + 1 \\ Q(S_t, A_t) & \leftarrow Q(S_t,A_t) + \frac{1}{N(S_t,A_t)}\left(G_t - Q(S_t, A_t)\right)\end{aligned}")
\end{aligned}")
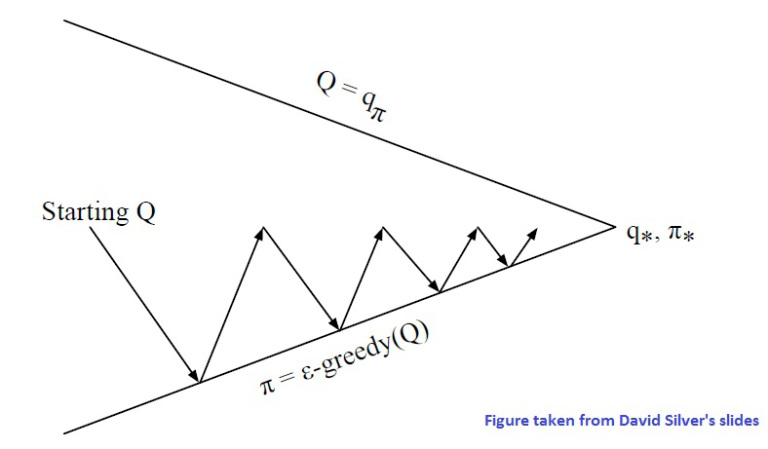
Note that in the above, we did not wait till the convergence of the value function over several episodes for each policy before improving the policy. We modify the policy after each episode. This is typical (more efficient??) in practice. The following figures illustrates this note:
Next improvement idea is the TD idea from model-free prediction. Here, we update ")
- Initialize
- For current state
- Observe reward
from environment.
- Choose action
(do not take action yet) based on the same policy (
- Refine
and
as
- Iterate the steps by taking
\leftarrow Q(S,A) + \alpha\left(R+\gamma Q(S',A')-Q(S,A)\right)")
The above algorithm is called Sarsa because of occurrence of letters 
")
Then, similar to 
} = R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^n Q\left(S_{t+n}\right)")
\leftarrow Q\left(S_t,A_t\right)+\alpha\left(q_t^{(n)}-Q\left(S_t,A_t\right)\right)")
And, similar to TD(
\sum\limits_{n=1}^{\infty}\lambda^{n-1}q_t^{(n)}")
and we update as follows:
\leftarrow Q\left(S_t,A_t\right)+\alpha\left(q_t^{\lambda}-Q\left(S_t,A_t\right)\right)")
Value Function Approximation
Let us consider what states look like in some practical scenarios. For example, in a chess game, the state consists of layout of the board with pieces. In an Atari game, the state consists of history of a few frames of images going back from current time.
As can be seen, the number of states is enormous (in the Atari game, a state is a vector of as many dimensions as there are pixels in all frames combined). Say, each frame is 80×80 pixels, each pixel takes values 0-255 (gray scale intensities) and we need the previous four frames to represent current state adequately (position, velocity etc). This gives a state space that has a whopping 
So, if we apply the RL learning algorithms directly, it is impractical to arrive at
Further, two states may be similar mostly, but differing in some insignificant ways. For example, in a chess game, the position of a certain piece may be irrelevant given the current set up of the game. Inherently,
To make reinforcement learning practical, we use function approximators to represent the 

In prediction for a given policy ")
")
![\left\lVert Q_{\pi}(S,a) - \hat{Q}_{\pi}(S,a,\mathbf{w})\right\rVert_{L^2}^2 = \mathbb{E}_{\pi}\left[\left(Q_{\pi}(S,a) - \hat{Q}_{\pi}(S,a,\mathbf{w})\right)^2\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5ClVert+Q_%7B%5Cpi%7D%28S%2Ca%29+-+%5Chat%7BQ%7D_%7B%5Cpi%7D%28S%2Ca%2C%5Cmathbf%7Bw%7D%29%5Cright%5CrVert_%7BL%5E2%7D%5E2+%3D+%5Cmathbb%7BE%7D_%7B%5Cpi%7D%5Cleft%5B%5Cleft%28Q_%7B%5Cpi%7D%28S%2Ca%29+-+%5Chat%7BQ%7D_%7B%5Cpi%7D%28S%2Ca%2C%5Cmathbf%7Bw%7D%29%5Cright%29%5E2%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left\lVert Q_{\pi}(S,a) - \hat{Q}_{\pi}(S,a,\mathbf{w})\right\rVert_{L^2}^2 = \mathbb{E}_{\pi}\left[\left(Q_{\pi}(S,a) - \hat{Q}_{\pi}(S,a,\mathbf{w})\right)^2\right]")
Assuming we know ")
 - \hat{Q}_{\pi}(S,a,\mathbf{w})\right){\triangledown}_{\mathbf{w}} \hat{Q}_{\pi}(S,a,\mathbf{w})")
In the above, we made one incorrect assumption, which is that we know
- In the Monte-carlo method, we use
- In TD(
to get
- In TD(
to get
\right){\triangledown}_{\mathbf{w}} \hat{Q}_{\pi}(S,a,\mathbf{w})")
 - \hat{Q}_{\pi}(S,a,\mathbf{w})\right){\triangledown}_{\mathbf{w}} \hat{Q}_{\pi}(S,a,\mathbf{w})")
\right){\triangledown}_{\mathbf{w}} \hat{Q}_{\pi}(S,a,\mathbf{w})")
(The presumed targets in TD methods are also dependent on
In practice, say, we have the following sequence of state-action pairs in a realization of the policy: , (S_2,a_2), \cdots, (S_{T-1}, a_{T-1})")
In each step, we update 
Does the stochastic gradient descent work when using presumed targets and highly correlated input state sequences? There are convergence issues that are addressed with batch method techniques like experience replay.
Example function approximators
An example type of function approximator is a linear function approximator. Here, if for each state-action pair ")
, \mathbf{x}_2(S,a),\cdots, \mathbf{x}_n(S,a)")
 = \begin{bmatrix} \mathbf{x}_1(S,a)\\ \mathbf{x}_2(S,a)\\ \vdots \\ \mathbf{x}_n(S,a)\end{bmatrix}")
then, we have a linear function approximator:
 = \mathbf{x}(S,a)^T\mathbf{w}=\sum\limits_{j=1}^n \mathbf{x}_j(S,a)\mathbf{w}")
Another example type of function approximator is a deep neural network. A deep neural network is a non-linear function approximator. Deep Neural Networks have proven highly successful in feature extraction in images. In the context of reinforcement learning, we are not thinking of a two phase approach where a neural network is first used to identify specific features in the
When we employ neural networks, we typically use a mini-batch of samples for SGD. We also employ the techniques of experience replay and fixed
With a DQN outputting ")
- Take action
according to
- Store the tuple
in a replay memory
- Sample random mini-batch of tuples from the replay memory (experience replay)
- Compute presumed targets with respect to fixed parameters
(fixed
- Minimize the objective function:
Do this by applying SGD on the mini-batch obtained from.
- Iterate
![\mathbb{E}_{\left(S,a,R,S'\right) \in D}\left[\left(R+\gamma\max\limits_{a'} \hat{Q}\left(S',a',\mathbf{w}^-\right)-\hat{Q}\left(S,a,\mathbf{w}\right)\right)^2\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5Cleft%28S%2Ca%2CR%2CS%27%5Cright%29+%5Cin+D%7D%5Cleft%5B%5Cleft%28R%2B%5Cgamma%5Cmax%5Climits_%7Ba%27%7D+%5Chat%7BQ%7D%5Cleft%28S%27%2Ca%27%2C%5Cmathbf%7Bw%7D%5E-%5Cright%29-%5Chat%7BQ%7D%5Cleft%28S%2Ca%2C%5Cmathbf%7Bw%7D%5Cright%29%5Cright%29%5E2%5Cright%5D&bg=ffffff&fg=000000&s=0 "\mathbb{E}_{\left(S,a,R,S'\right) \in D}\left[\left(R+\gamma\max\limits_{a'} \hat{Q}\left(S',a',\mathbf{w}^-\right)-\hat{Q}\left(S,a,\mathbf{w}\right)\right)^2\right]")
In the above, we use 
\leftarrow Q(S,A) + \alpha\left(R+\gamma \max\limits_{A'}Q(S',A')-Q(S,A)\right)")
Observe that two actions need to be chosen in the algorithms (both SARSA and 
Policy gradients
In the above algorithms, we first determine the ")
In algorithms based on policy gradients, we bypass the optimal value function and aim to get to an optimal policy directly.
One primary advantage of policy gradient based algorithms over value-function based algorithms is in the scenarios with continuous action spaces or many many (high-dimensional) discrete actions. When we have continuous action space, determining the maximum of
In policy gradient approach, we parameterize a policy using parameters 
Average value objection function:
Average reward per time-step objective function:  = \sum\limits_s d_{\pi_{\theta}}(s)\sum\limits_{a}\pi_{\theta}(s,a)R_{s,a}")
 = \sum\limits_s d_{\pi_{\theta}}(s)V_{\pi_{\theta}}(s)")
In the above, 
")
")

An optimal policy is one with the highest value of objective function. To determine
Assuming average reward per time-step objective function, that is  = \sum\limits_s d(s)\sum\limits_{a}\pi_{\theta}(s,a)R_{s,a}")
![\begin{aligned} \nabla_{\theta} J(\theta) &= \sum\limits_s d(s) \sum\limits_{a}\nabla_{\theta}\pi_{\theta}(s,a)R_{s,a} \\ &= \sum\limits_s d(s) \sum\limits_{a}\pi_{\theta}(s,a)\nabla_{\theta}\log\pi_{\theta}(s,a)R_{s,a} \\ &= \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)r\right]\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cnabla_%7B%5Ctheta%7D+J%28%5Ctheta%29+%26%3D+%5Csum%5Climits_s+d%28s%29+%5Csum%5Climits_%7Ba%7D%5Cnabla_%7B%5Ctheta%7D%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29R_%7Bs%2Ca%7D+%5C%5C+%26%3D+%5Csum%5Climits_s+d%28s%29+%5Csum%5Climits_%7Ba%7D%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29%5Cnabla_%7B%5Ctheta%7D%5Clog%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29R_%7Bs%2Ca%7D+%5C%5C+%26%3D+%5Cmathbb%7BE%7D_%7B%5Cpi_%7B%5Ctheta%7D%7D%5Cleft%5B%5Cnabla_%7B%5Ctheta%7D%5Clog%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29r%5Cright%5D%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0 "\begin{aligned} \nabla_{\theta} J(\theta) &= \sum\limits_s d(s) \sum\limits_{a}\nabla_{\theta}\pi_{\theta}(s,a)R_{s,a} \\ &= \sum\limits_s d(s) \sum\limits_{a}\pi_{\theta}(s,a)\nabla_{\theta}\log\pi_{\theta}(s,a)R_{s,a} \\ &= \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)r\right]\end{aligned}")
In deriving the above, we used the following fact(?):
 &= \pi_{\theta}(s,a)\frac{\nabla_{\theta}\pi_{\theta}(s,a)}{\pi_{\theta}(s,a)} \\ &= \pi_{\theta}(s,a)\nabla_{\theta}\log\pi_{\theta}(s,a)\end{aligned}")
The expectation shown above is across all states and actions. The quantity ")
A policy gradient theorem generalizes the above to multi-step scenarios as follows:
![\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)Q_{\pi_{\theta}}(s,a)\right]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D_%7B%5Cpi_%7B%5Ctheta%7D%7D%5Cleft%5B%5Cnabla_%7B%5Ctheta%7D%5Clog%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29Q_%7B%5Cpi_%7B%5Ctheta%7D%7D%28s%2Ca%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)Q_{\pi_{\theta}}(s,a)\right]")
An algorithm called Monte-Carlo policy gradient or REINFORCE can be used for episodic(only?) scenarios. The algorithm goes through episodes, and updates the policy by sampling the expectation (stochastic gradient ascent philosophy where rather than averaging across all states and actions, we consider one or a mini-batch of state-action pair(s)) and sampling the ")
The algorithm is as follows:
- Initialize
- Iterate through several(?) episodes
where action
is determined by policy
- Iterate through timesteps
through
- Update
, where
is a unbiased(?) sample of
- Update
- Iterate through timesteps

")
Actor-critic methods
Monte-carlo method involves a high variance on
In the Actor-critic methods, there is a critic that approximates (and updates) the ")

Thus, in actor-critic methods, we use an approximate policy gradient namely
![\nabla_{\theta} J(\theta) \approx \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)Q_w(s,a)\right]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Ctheta%29+%5Capprox+%5Cmathbb%7BE%7D_%7B%5Cpi_%7B%5Ctheta%7D%7D%5Cleft%5B%5Cnabla_%7B%5Ctheta%7D%5Clog%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29Q_w%28s%2Ca%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "\nabla_{\theta} J(\theta) \approx \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)Q_w(s,a)\right]")
We can estimate and update
Here, we give a simple actor-critic algorithm where in  = \phi(s,a)^Tw")
The algorithm is as follows:
- Initialize
- Sample action
- Iterate
- Take action
- Observe reward
, and next state
- Sample action
for state
- Take action
 - Q_w(s,a)")
Q_w(s,a)")
")

A variant of the above algorithm uses advantage function  - V_{\pi_{\theta}}(s)")
![\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)A_{\pi_{\theta}}(s,a)\right]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D_%7B%5Cpi_%7B%5Ctheta%7D%7D%5Cleft%5B%5Cnabla_%7B%5Ctheta%7D%5Clog%5Cpi_%7B%5Ctheta%7D%28s%2Ca%29A_%7B%5Cpi_%7B%5Ctheta%7D%7D%28s%2Ca%29%5Cright%5D&bg=ffffff&fg=000000&s=0 "\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta}\log\pi_{\theta}(s,a)A_{\pi_{\theta}}(s,a)\right]")